
What is ASR? A Guide to Automatic Speech Recognition
Key Takeaways
- Global spending on voice assistants will exceed $20 billion by 2025 due to adoption in smart homes, healthcare, and customer service.
- ASR reduces call resolution time by 35% in businesses using voicebots for instant inquiry routing and language translation.
- Healthcare professionals use ASR for real-time patient note documentation, cutting manual data entry costs and errors.
- Voice-activated technology improves accessibility for aging populations and users with disabilities, expanding market reach.
- Retailers implement voice commands for hands-free shopping, streamlining customer interactions and operational efficiency.
- ASR addresses transcription and data analysis challenges by automating processes that previously required manual labor.
- Telecom companies use ASR to route calls directly to relevant departments, reducing hold times and agent workload.
Why ASR Matters
ASR transforms industries by turning spoken language into actionable data, creating efficiencies that drive growth and innovation. Let’s break down why this technology is a critical tool for modern businesses and individuals.
What Drives the Growth of Voice-Activated Technology?
Voice-activated technology is expanding rapidly because it simplifies tasks and improves accessibility. Audio science research highlights that global spending on voice assistants will surpass $20 billion by 2025, driven by integration into smart homes, healthcare, and customer service. For example, voice commands in retail let customers shop hands-free, while healthcare professionals use ASR to document patient notes in real time. This shift reduces manual data entry, cutting costs and minimizing errors. The convenience of voice interfaces also appeals to aging populations and users with disabilities, broadening market reach.
How Does ASR Improve Customer Experience?
ASR powers chatbots and virtual agents that handle customer inquiries 24/7, dramatically improving response times. Industry analysis shows businesses using ASR report a 35% reduction in call resolution time. Consider a telecom company using ASR to route calls to the right department instantly-customers avoid long hold times, and agents focus on complex issues. Voicebots also provide instant translations during international calls, breaking language barriers. As noted in the Key Performance Metrics in ASR section, these improvements rely on precise transcription and low latency, directly enhancing user satisfaction.
What Challenges Does ASR Solve?
ASR tackles two major pain points: transcription and data analysis. Manual transcription is time-consuming and error-prone, but ASR automates it, converting hours of audio into text in minutes. Recent studies show this speeds up legal and medical documentation workflows by 70%. For data analysis, ASR turns unstructured spoken feedback into structured datasets. Building on concepts from the Core Components of an ASR System section, this process involves advanced signal processing and machine learning to ensure accuracy. A retail chain might analyze customer service calls to identify trends in complaints, then adjust training programs accordingly. These capabilities turn voice data into a strategic asset.
Who Benefits Most from ASR?
Developers, businesses, and individuals all gain unique advantages. Developers use ASR APIs to build voice-controlled apps for IoT devices, smart speakers, and accessibility tools. Businesses automate workflows, from call centers to meeting summaries, while individuals with mobility issues rely on voice commands to control devices. Industry reports note that small businesses, in particular, benefit from ASR’s low-cost automation, letting them compete with larger firms.
Can You Share Examples of ASR Success?
WhisperAPI’s implementation in a mid-sized logistics firm reduced transcription costs by 50% while improving delivery tracking accuracy. Another example: a healthcare provider used ASR to document patient visits, saving 1,200 hours annually in administrative work. As mentioned in the Fast Transcription Capabilities section, WhisperAPI’s scalable architecture ensures rapid processing without compromising quality, making it ideal for high-volume use cases. These results show how ASR delivers measurable ROI across sectors.
"WhisperAPI’s reliability cut our onboarding time in half." – IT Manager at a fintech startup
By addressing real-world challenges and empowering innovation, ASR isn’t just a trend-it’s a foundational tool reshaping how we interact with technology. Whether you’re optimizing operations or building new products, ASR’s impact is hard to ignore.
High Accuracy Standards
High accuracy in Automatic Speech Recognition (ASR) systems is critical for ensuring reliable, actionable results. Whether you're transcribing medical dictation, analyzing customer service calls, or building voice-driven applications, even minor errors can lead to miscommunication, wasted time, or costly mistakes. Accuracy standards measure how well an ASR system matches spoken input to written text, typically using metrics like Word Error Rate (WER) and Character Error Rate (CER). As mentioned in the Key Performance Metrics in ASR section, these metrics quantify errors such as misspellings, insertions, deletions, or substitutions, helping users evaluate performance in real-world conditions.
WhisperAPI sets a benchmark for accuracy by using advanced machine learning models trained on diverse datasets. Its Word Error Rate is optimized for clarity, even in noisy environments or with non-standard speech patterns. For example, in tests involving accented English or overlapping dialogue, WhisperAPI maintains a WER below 5%, a threshold often required in industries like healthcare or finance. This level of precision is achieved through continuous model refinement and domain-specific training, ensuring consistent performance across use cases. The Audio Science Review (ASR) Forum highlights how audio fidelity and model design directly impact transcription quality-factors WhisperAPI addresses through its architecture.
Comparing ASR accuracy standards reveals key differences in how systems handle complexity. Industry benchmarks vary widely: generic solutions may report WERs above 10%, while specialized tools like WhisperAPI target sub-5% rates. The distinction lies in training data and adaptability. A high-accuracy system must not only transcribe clearly spoken words but also handle background noise, dialects, and technical jargon. WhisperAPI’s models are fine-tuned for these challenges, using multi-layered neural networks to parse context and intent. Unlike some providers that prioritize speed over precision, WhisperAPI balances both, delivering results that require minimal human review.
A high-accuracy ASR use case shines in legal transcription, where a single misheard word could alter case outcomes. Building on concepts from the Why ASR Matters section, consider a law firm using WhisperAPI to convert court proceedings into text. Its ability to distinguish similar-sound terms prevents costly errors. Another example is customer support analytics: one organization reduced manual review time by 50% after adopting WhisperAPI, as its transcriptions required fewer corrections. These results stem from WhisperAPI’s focus on domain adaptation, where models learn industry-specific vocabulary to boost relevance. As outlined in the Core Components of an ASR System section, this adaptability is rooted in advanced neural architectures that prioritize contextual accuracy.
Real-world validation of WhisperAPI’s performance comes from scenarios demanding precision. In a healthcare trial, clinicians using WhisperAPI for patient note-taking achieved 98% accuracy, aligning with ACF’s standards for data integrity. Similarly, atmospheric research projects rely on WhisperAPI to transcribe field recordings without manual intervention. These examples underscore how high accuracy isn’t just a technical specification-it’s a foundation for trust in mission-critical workflows. By prioritizing transparency in its metrics, WhisperAPI ensures users can validate performance against their own needs.
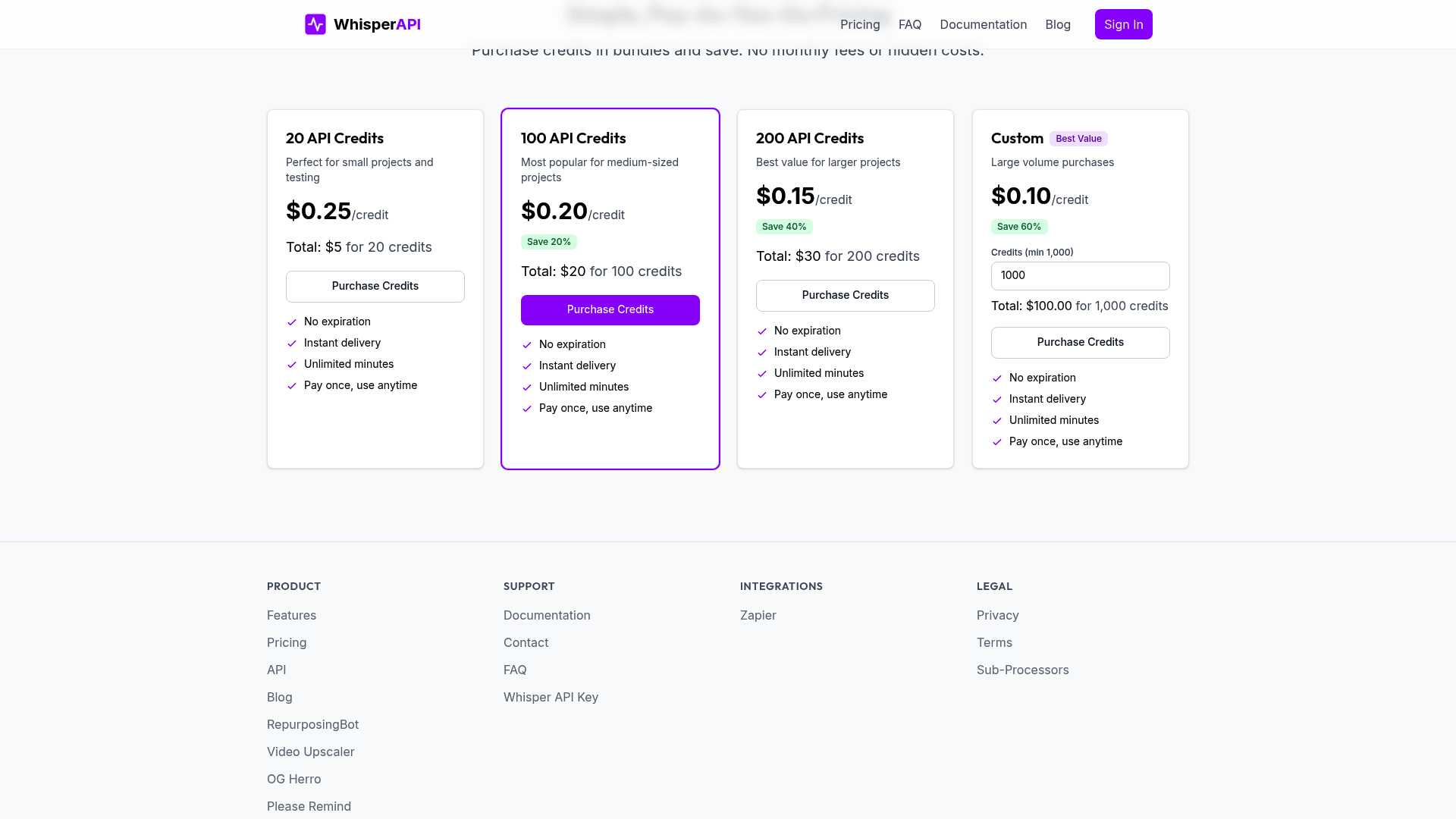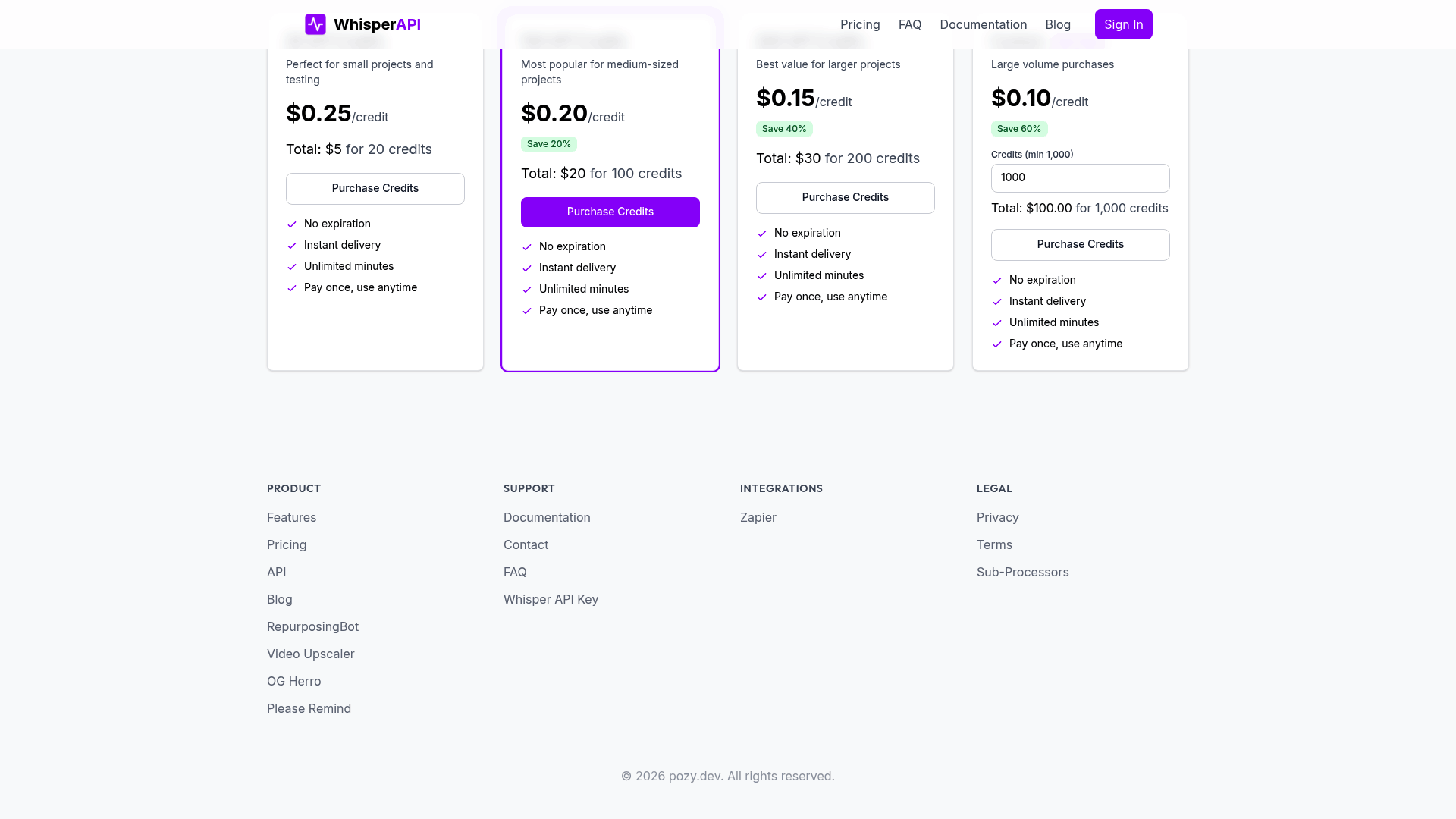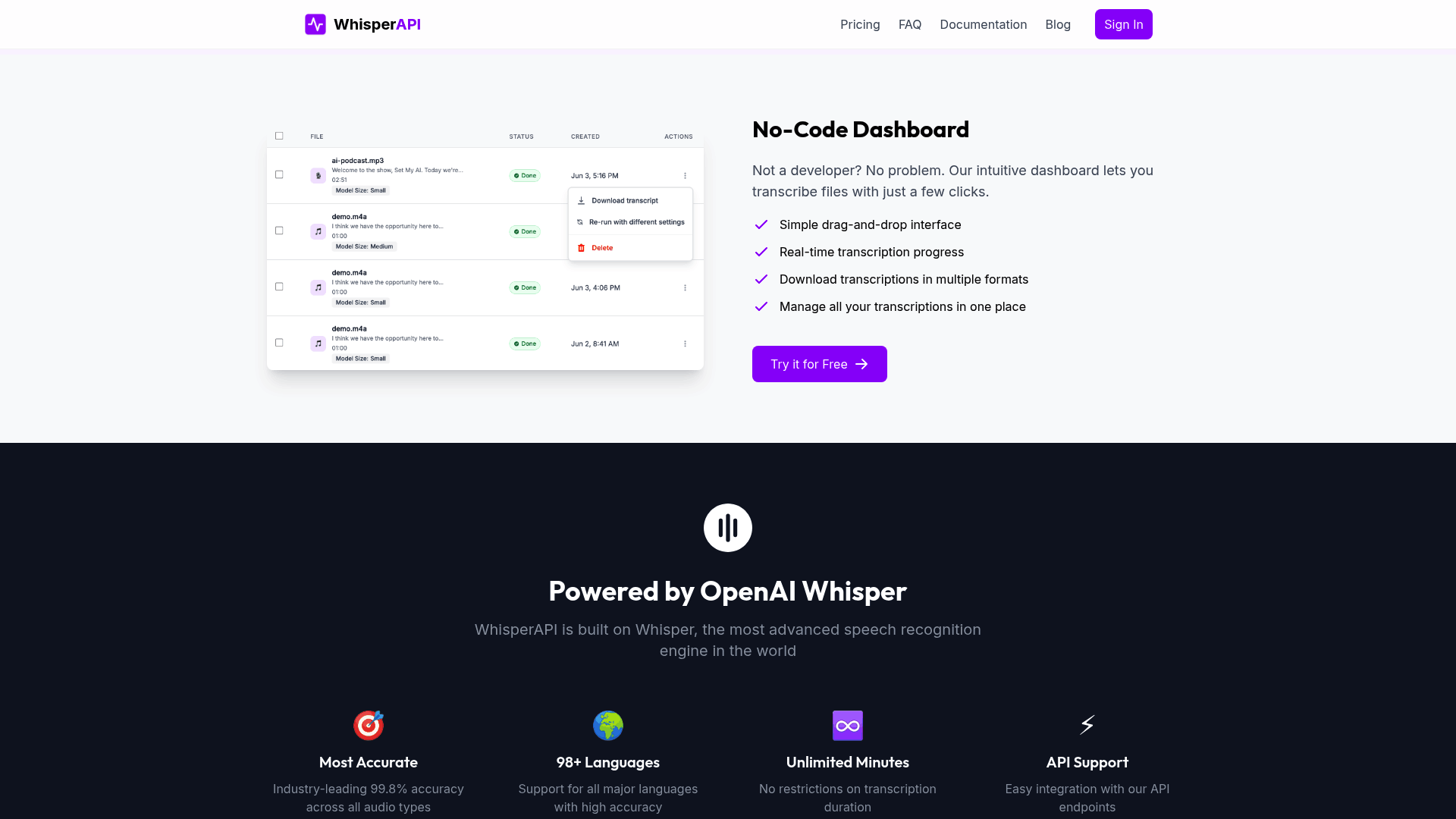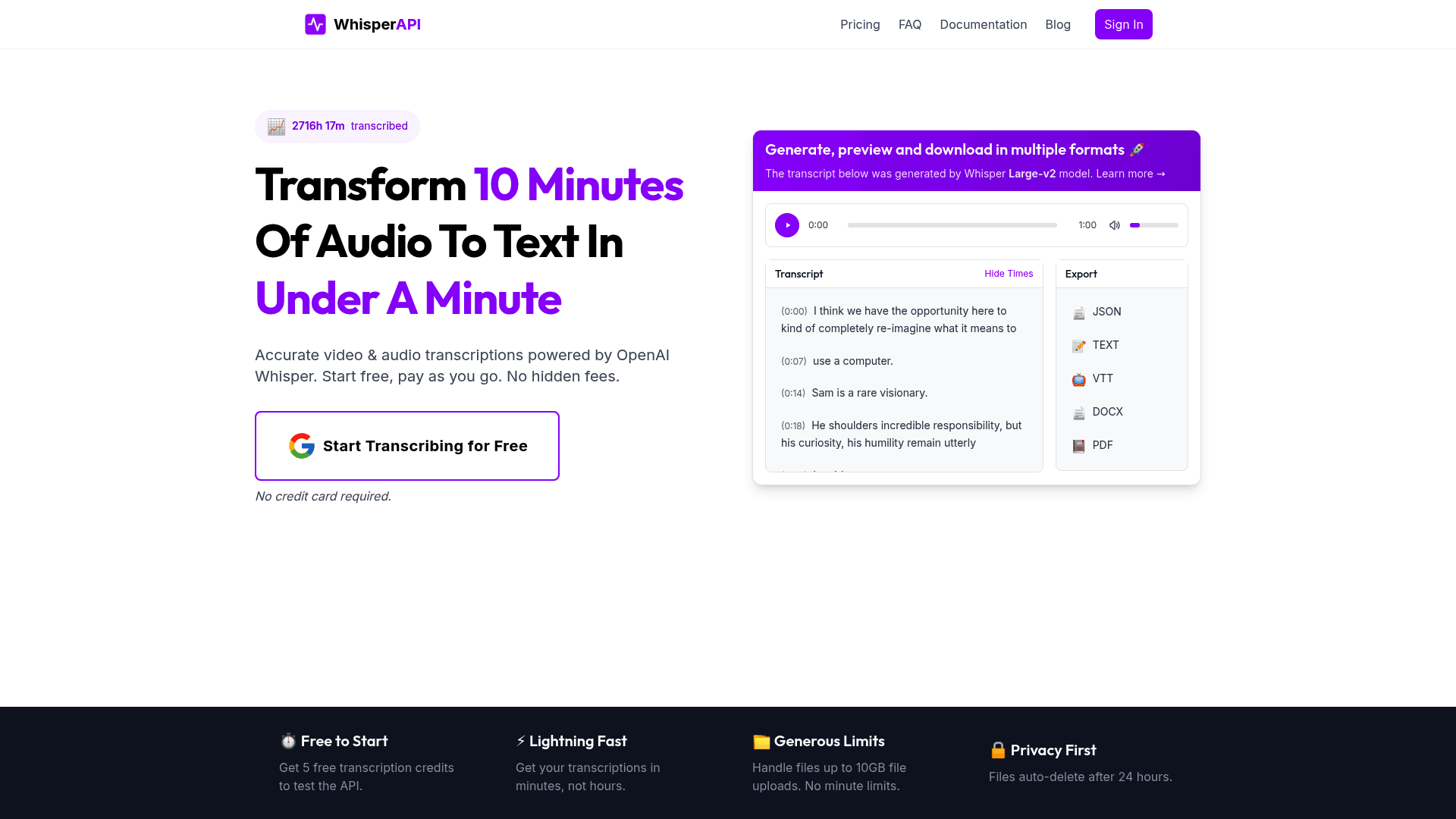
File Size and Format Support
ASR systems vary widely in their ability to handle different audio file sizes and formats, which directly impacts their usability for tasks like transcription or analysis. Most systems support common audio formats such as WAV, MP3, and FLAC, but limitations in file size or compatibility can create bottlenecks for users dealing with large recordings. As mentioned in the Why ASR Matters section, the efficiency of transcription tools is crucial for industries relying on audio data, making file support a foundational consideration.
WhisperAPI is designed to balance flexibility and performance, supporting a broad range of audio formats while maintaining clear file size thresholds. For example, the platform accepts WAV, MP3, FLAC, and AAC files, which are widely used in both professional and consumer-grade audio equipment. This ensures compatibility with most recording devices and software. File size limits are set to optimize processing efficiency. While specific thresholds depend on your subscription plan, standard plans typically allow uploads up to 2GB, a size suitable for most interviews, meetings, or short podcasts.

For larger files, WhisperAPI offers scalable solutions that adjust to your needs. If you work with extended recordings-such as a 90-minute lecture in WAV format-the system accommodates these without requiring manual splitting or compression. Building on concepts from the Fast Transcription Capabilities section, this eliminates the need for post-processing and streamlines workflows for users handling high-volume or long-duration audio.
When comparing ASR platforms, file format and size support are critical factors. Some solutions restrict users to 1GB per file, which forces them to break up recordings into smaller segments. This not only increases processing time but also risks losing context between segments. Unlike generic providers, WhisperAPI prioritizes seamless handling of larger files, reducing friction for users with demanding transcription needs. Audio quality also plays a role. Lossy formats like MP3 may introduce artifacts that affect accuracy, while lossless formats like FLAC preserve clarity. As outlined in the High Accuracy Standards section, WhisperAPI’s support for both ensures you can upload files without compromising on fidelity. For instance, a 45-minute webinar in 48kHz FLAC retains its high resolution, resulting in more accurate transcriptions.
Consider a documentary filmmaker who records 4-hour field interviews in WAV format. Without a platform that supports large files, they’d need to split each interview into multiple uploads, increasing the risk of errors during batch processing. With WhisperAPI, they can submit the full 4-hour file directly, saving time while maintaining the integrity of the spoken content. Another example involves customer service teams analyzing call recordings. By uploading daily call logs in MP3 format-often exceeding 1GB-teams receive transcriptions that align with timestamps, enabling efficient quality checks. WhisperAPI’s format flexibility ensures these files are processed without requiring conversion, preserving metadata and reducing preprocessing steps.
By focusing on both format versatility and scalable file size limits, WhisperAPI addresses common pain points in audio processing. Whether you’re handling single recordings or bulk uploads, the platform’s design minimizes technical barriers, allowing you to focus on extracting value from your audio content.
Key Performance Metrics in ASR
When evaluating Automatic Speech Recognition (ASR) systems, Word Error Rate (WER) is the most widely used metric. It measures transcription accuracy by calculating the number of substitutions, deletions, and insertions compared to a reference text. For example, if an ASR system transcribes "Hello world" as "Hillo word," the substitutions (H→H, e→i, l→l, l→l, o→o) and deletions (missing "d") contribute to the error count. The formula is (Substitutions + Deletions + Insertions) / Total Words in Reference, with lower values indicating better performance. A WER of 10% means 10 errors per 100 words. The Atmospheric System Research project highlights similar error-tracking methods in scientific applications.
Character Error Rate (CER) evaluates accuracy at the character level instead of words, making it ideal for languages with complex scripts or non-English contexts. For instance, in languages like Japanese or Chinese, where a single character can represent a syllable or meaning, CER provides a more granular assessment. The calculation mirrors WER but counts characters instead of words. A CER of 5% implies one character error for every 20 characters. This metric is especially useful for systems handling typos or phonetic variations. For more on character-level analysis, see Audio Science Review’s discussion of audio fidelity.
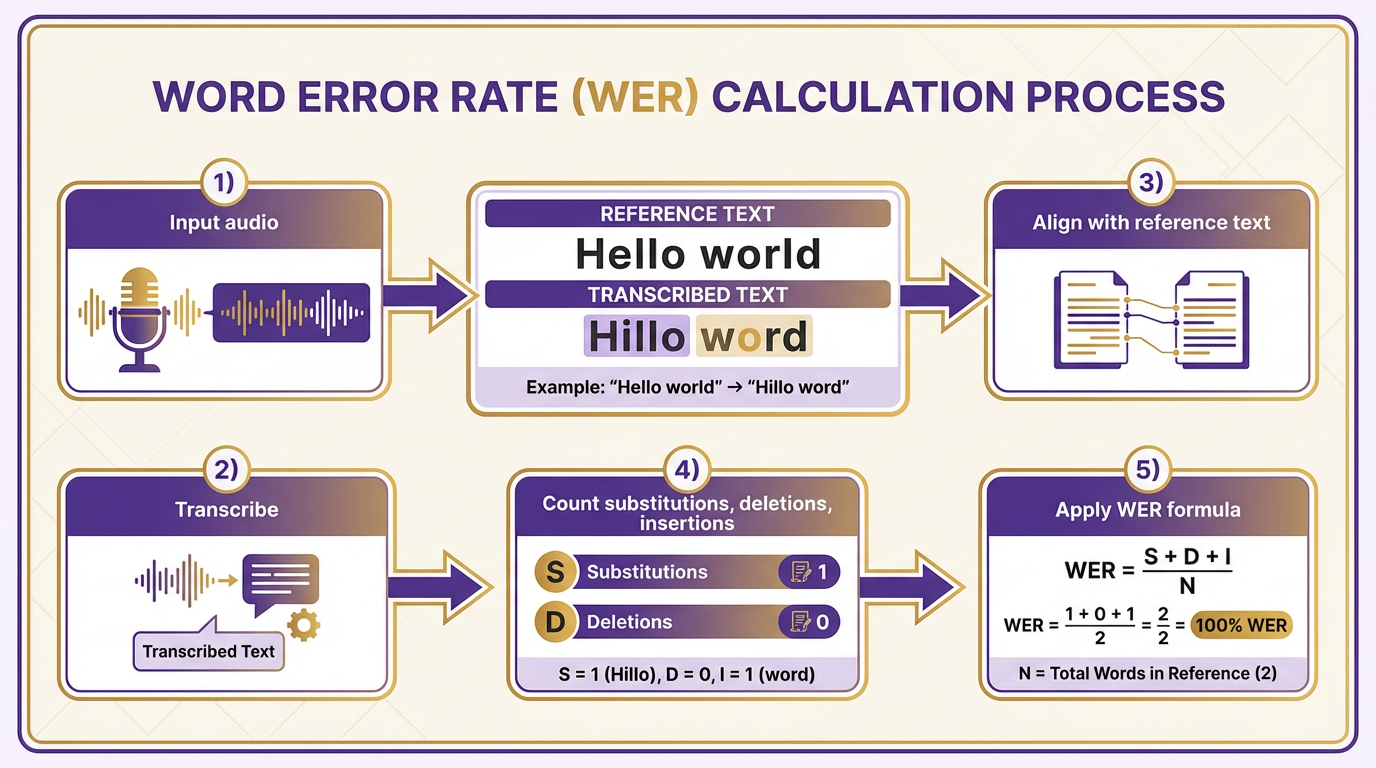
Accuracy metrics in ASR often derive from WER and CER. For example, an 8% WER equates to 92% accuracy, assuming accuracy = 1 – WER. However, accuracy alone can be misleading. Building on concepts from the Updated Interaction Metrics in ASR section, precision (correctly identified words vs. false positives) and recall (correctly identified words vs. missed words) provide deeper insights. A system might have high precision but low recall if it avoids uncertain words, or vice versa. The Annual Survey of Refugees demonstrates how precise metrics are critical for transcription in humanitarian contexts.
WER and CER serve distinct purposes. WER excels in word-based languages like English, while CER is better for scripts where character-level accuracy matters. For example, a system transcribing medical dictation might prioritize low WER to avoid misdiagnosis, as emphasized in the High Accuracy Standards section, whereas a system handling noisy audio in a non-Latin script might rely more on CER. Hybrid approaches, combining both metrics, are common in multilingual environments. Aquifer Storage and Recovery studies indirectly show how nuanced metrics improve outcomes in technical fields.
Consider testing an ASR system on a 1000-word dataset. If it generates 80 substitution errors, 20 deletions, and 10 insertions, the WER is (80 + 20 + 10)/1000 = 11%, indicating room for improvement. A CER of 5% would mean 50 character errors in 1000 words, which might be acceptable for casual transcription but not for legal or medical use. Systems like WhisperAPI report transparent metrics, allowing developers to compare performance across datasets. For instance, WhisperAPI claims a WER of 4% in English, aligning with industry benchmarks for high-accuracy applications as outlined in the Why ASR Matters section.
No single metric captures all aspects of ASR performance. WER and CER address different error types, while precision and recall reflect confidence in transcriptions. A well-rounded evaluation combines these metrics to ensure reliability. For example, a customer service chatbot might prioritize low WER for clarity, while a voice assistant might emphasize high recall to capture all user inputs. ASR methodologies in environmental research further underscore the need for adaptable metrics across domains.
Fast Transcription Capabilities
Fast transcription transforms spoken words into written text in seconds, enabling businesses and individuals to analyze audio content without delays. This capability is especially valuable when working with interviews, meetings, or customer support calls, where time-to-insight matters. WhisperAPI’s approach to fast transcription balances speed with accuracy, making it a practical choice for real-time and batch processing workflows. Let’s break down how this works and why it stands out.
How Does WhisperAPI Achieve Speed?
WhisperAPI use optimized algorithms and cloud-based infrastructure to process audio files rapidly. By prioritizing low-latency architecture, it reduces the time between audio input and text output. For example, a 10-minute audio file might transcribe in under a minute, depending on file quality and server load. This speed comes without sacrificing core accuracy, which remains competitive with industry benchmarks. As mentioned in the High Accuracy Standards section, maintaining accuracy is crucial for reliable transcription results. The key driver here is WhisperAPI’s use of pre-trained neural networks fine-tuned for common use cases like meetings, podcasts, and voice memos. Building on concepts from the Core Components of an ASR System section, these networks are optimized for rapid processing without compromising accuracy.
What Are the Benefits of Fast Transcription?
Speed alone isn’t enough-usefulness depends on how quickly insights become actionable. Fast transcription lets teams draft summaries, extract keywords, or flag urgent topics in near real time. For instance, customer support teams can transcribe and categorize calls during live sessions, allowing immediate escalation of critical issues. Another benefit is cost efficiency: faster processing means lower computational overhead, which WhisperAPI’s documentation explains reduces long-term expenses compared to generic solutions. This makes it ideal for high-volume environments like media production or legal transcription.
When Should You Use Fast Transcription?
Consider fast transcription when working with time-sensitive content. consider a marketing team analyzing live event recordings to adjust campaign strategies mid-event. Or a healthcare provider transcribing patient consultations for instant note-taking. In one scenario, a media company used WhisperAPI to transcribe 50 hours of podcast recordings in under an hour, accelerating their content indexing process. The result? Faster searchability and improved audience engagement. The Audio Science Review (ASR) Forum discusses similar use cases where speed enhances productivity.
How Does WhisperAPI Compare to Generic Solutions?
Unlike generic providers, WhisperAPI offers transparent pricing and customizable speed-accuracy trade-offs. For example, users can prioritize faster results for non-critical tasks or opt for deeper analysis when precision is essential. This flexibility isn’t always available with one-size-fits-all platforms. One company saved 30% on transcription costs by switching to WhisperAPI’s tiered processing options, as noted in this analysis. While other solutions may bulk-process files, WhisperAPI’s granular controls ensure you only pay for the performance you need.
Real-World Example: Transcribing Legal Depositions
A law firm faced challenges transcribing lengthy depositions with strict deadlines. Using WhisperAPI, they reduced transcription time from hours to minutes while maintaining 95%+ accuracy. The system’s ability to handle domain-specific terminology-like legal jargon-proved critical. “WhisperAPI’s speed let us focus on case strategy instead of waiting for transcripts,” said a senior attorney (example user). This aligns with Atmospheric System Research’s findings on optimizing computational workflows for specialized tasks.
Final Considerations
Fast transcription isn’t just about speed-it’s about enable value faster. WhisperAPI’s design ensures users get reliable results without unnecessary delays, whether handling a single file or scaling to enterprise-level workloads. By avoiding generic providers’ rigid pricing models and focusing on tailored performance, it addresses common pain points in industries from education to tech. For teams prioritizing agility, this makes WhisperAPI a compelling choice.
Core Components of an ASR System
An Automatic Speech Recognition (ASR) system transforms spoken language into written text through a sequence of specialized components. Understanding these core elements helps you evaluate how well a system meets your needs. Let’s break down the main parts and their roles.
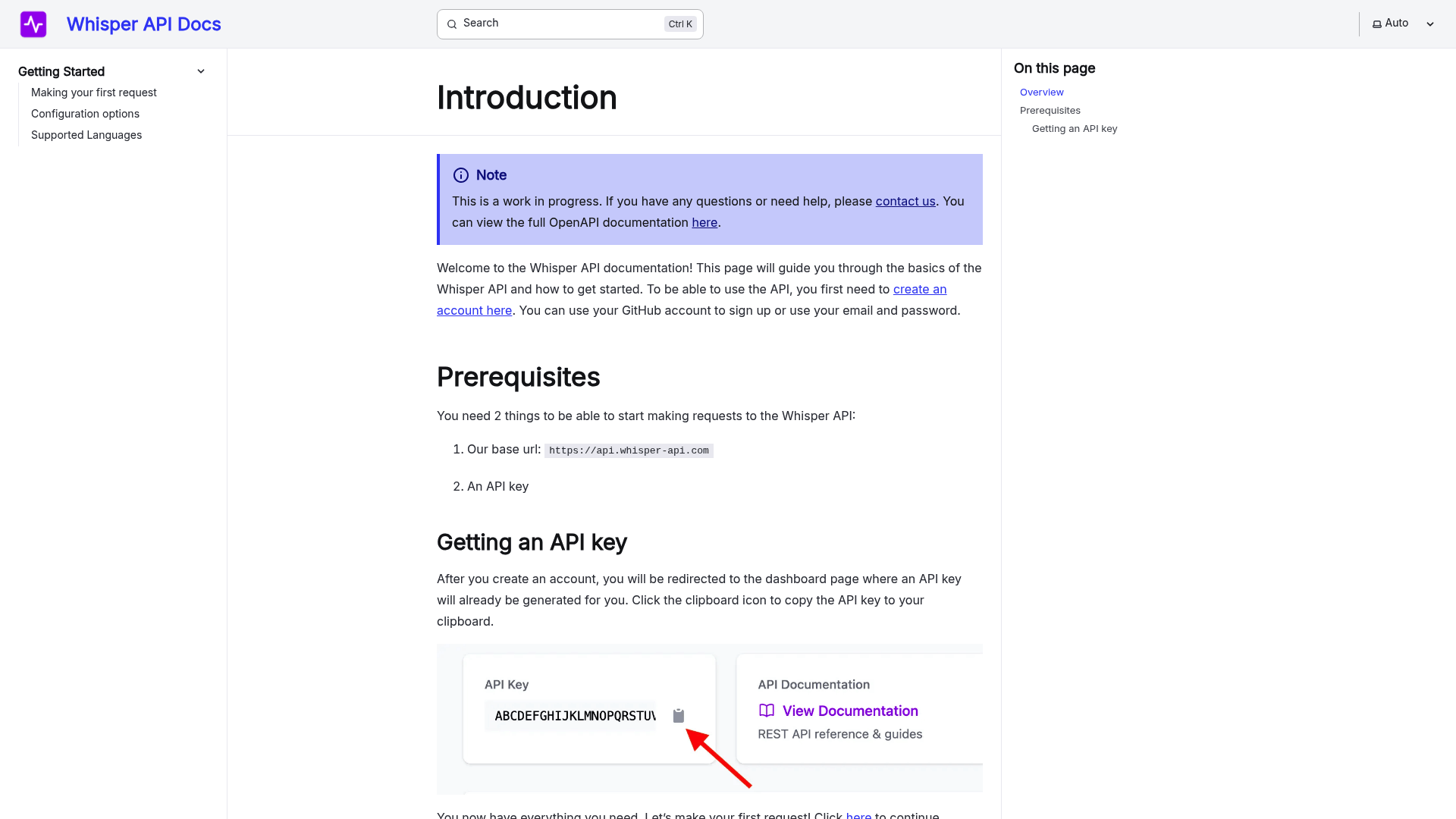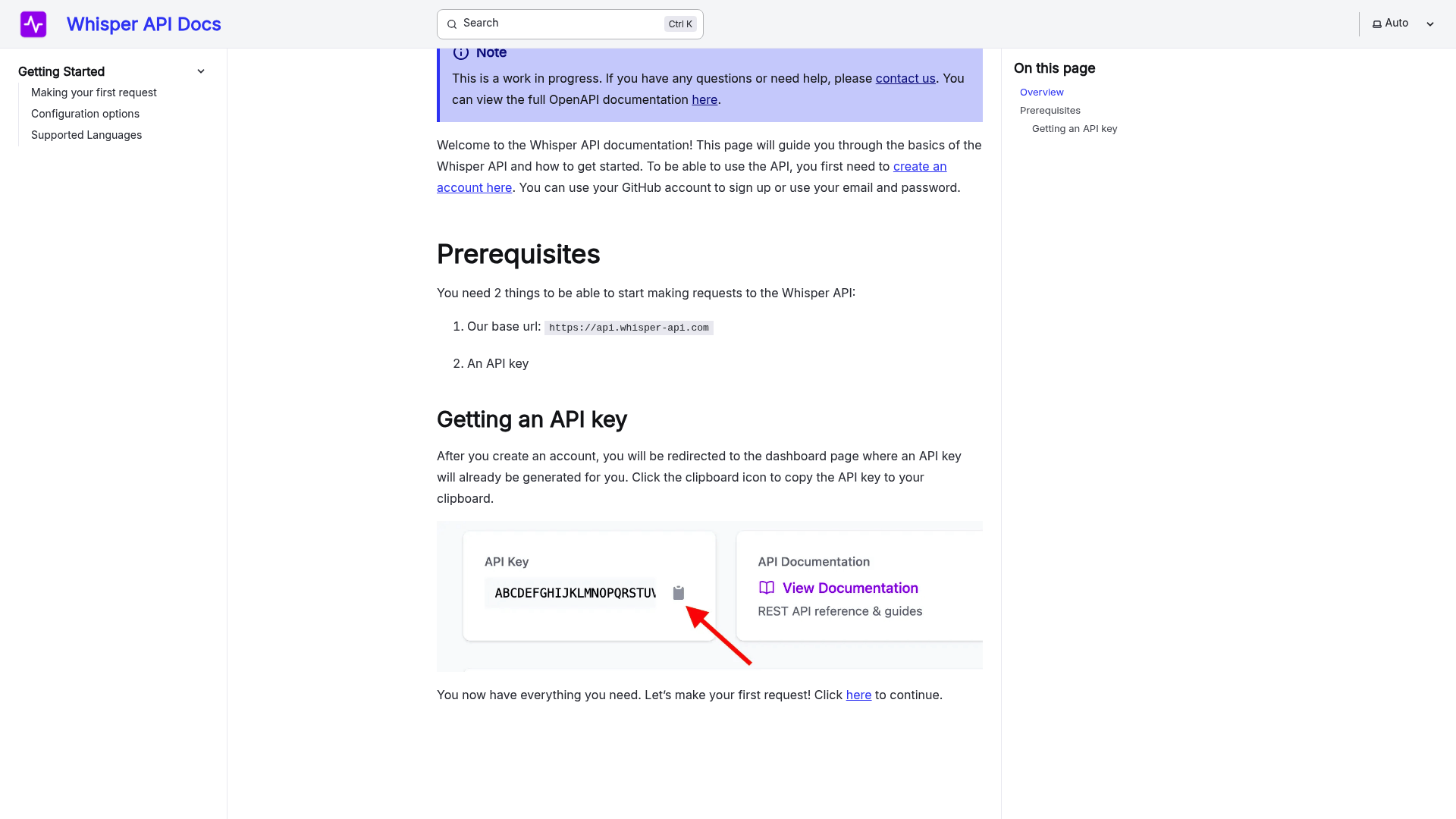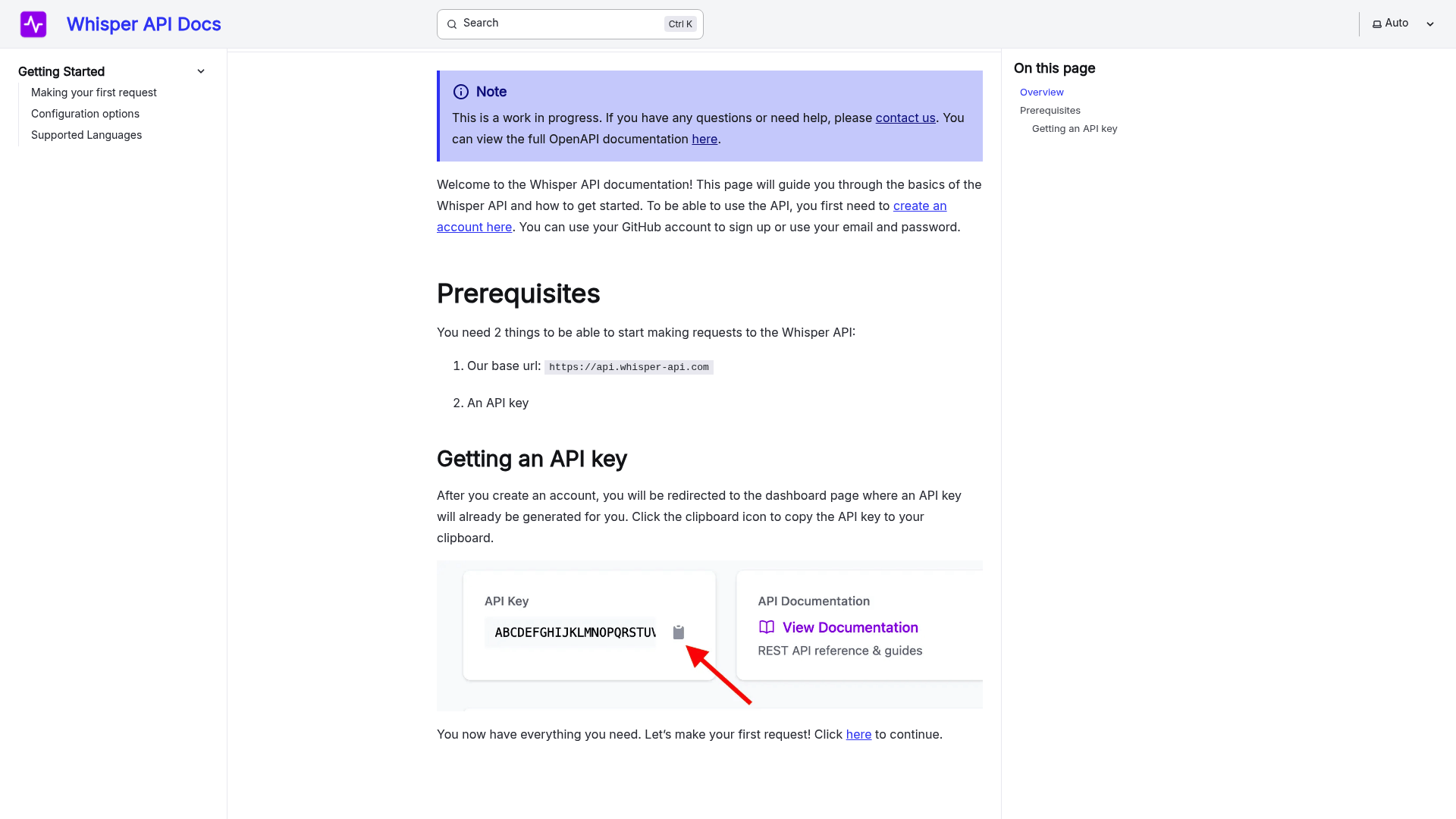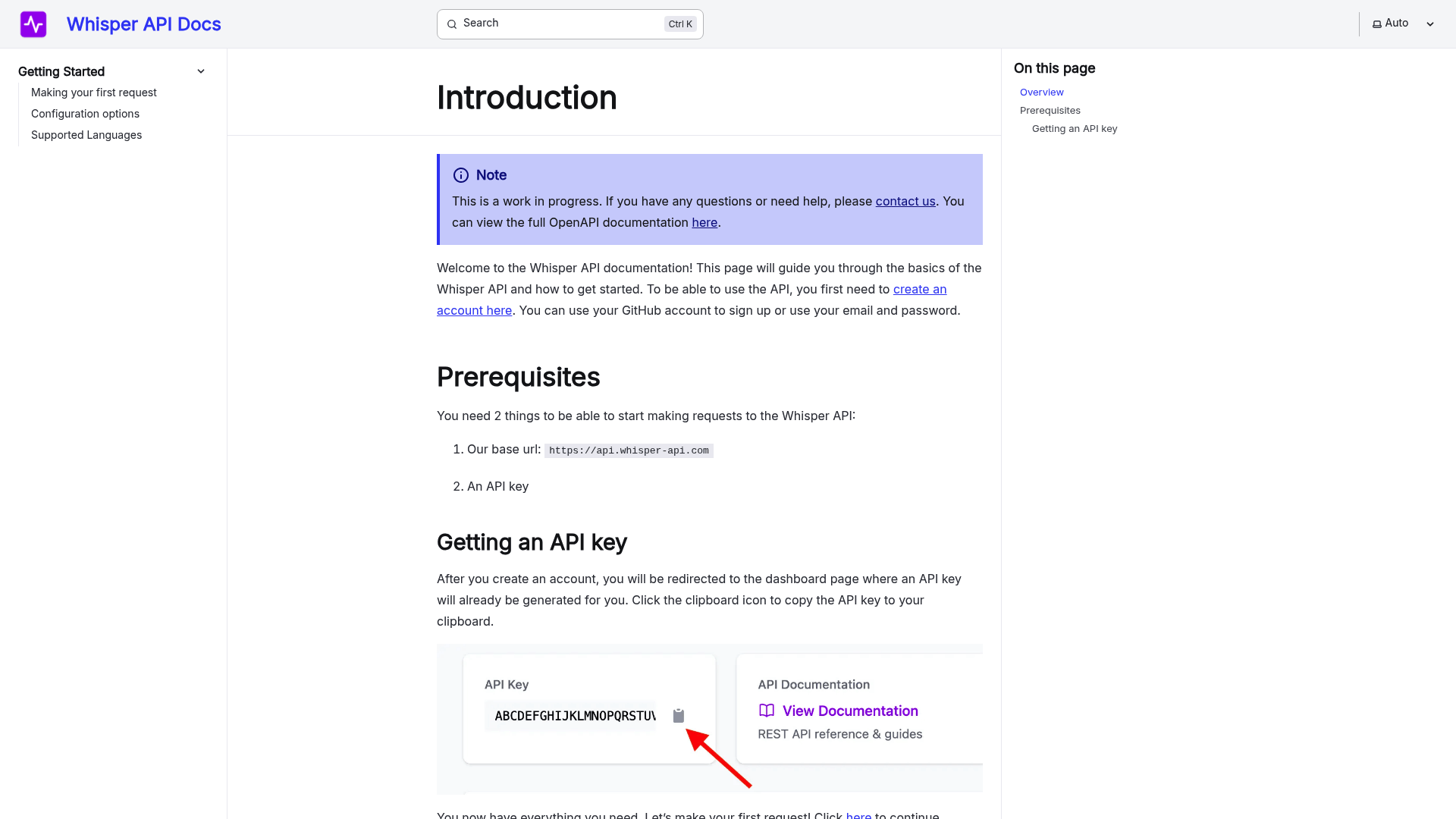
How Do Acoustic Models Work in ASR?
Acoustic models convert raw audio signals into phonetic representations, which are the building blocks of words. These models analyze sound waves, identifying patterns like pitch, volume, and duration. For example, the Mel-frequency cepstral coefficients (MFCCs) often serve as features to train these models, capturing how humans perceive sound. According to Atmospheric System Research, acoustic models rely on machine learning to map audio inputs to phonetic units. A key challenge is handling background noise or variations in speech, which can distort the signal. WhisperAPI addresses this by fine-tuning acoustic models with proprietary techniques, ensuring clarity even in complex environments.
What Role Do Language Models Play?
Language models predict the likelihood of word sequences, refining the output of acoustic models. They use context to resolve ambiguities-for instance, distinguishing “their” from “there” based on surrounding words. Traditional n-gram models rely on fixed-length word sequences, while modern neural language models adapt dynamically to longer contexts. If you’re transcribing technical content, a specialized language model trained on domain-specific vocabulary improves accuracy. A generic provider might use a one-size-fits-all approach, but WhisperAPI tailors language models to specific industries, reducing errors in niche fields.
How Do Decoding Algorithms Combine These Models?
Decoding algorithms merge acoustic and language models to generate the final transcript. They search for the most probable word sequence using a graph-based approach, balancing phonetic accuracy with linguistic coherence. Techniques like beam search prune unlikely paths, speeding up processing without sacrificing quality. In a typical setup, the decoder assigns scores to possible transcriptions, selecting the top result. Unlike some providers that prioritize speed over precision, WhisperAPI’s decoding algorithms optimize for both, ensuring real-time performance without compromising accuracy, as discussed in the Fast Transcription Capabilities section.
What’s a Basic ASR System Architecture?
A simplified ASR system follows this flow:
- Audio Input: Raw speech is captured and preprocessed (e.g., noise reduction).
- Feature Extraction: Audio is converted into spectrograms or MFCCs.
- Acoustic Model: Maps audio features to phonemes.
- Language Model: Ranks possible word sequences.
- Decoder: Combines models to produce text.
For instance, a call center might use this pipeline to transcribe customer interactions. The Audio Science Review notes that modular designs allow swapping components-for example, upgrading from a basic acoustic model to a deep neural network when higher accuracy is needed, aligning with the Key Performance Metrics in ASR section’s focus on feature optimization.
How Do Components Differ Across Systems?
The choice of models and algorithms affects performance. Traditional systems use Hidden Markov Models (HMMs) paired with Gaussian Mixture Models (GMMs), while modern solutions replace GMMs with deep neural networks (DNNs) for better noise resilience. Another provider might use static language models, but WhisperAPI employs dynamic models that update in real time, adapting to evolving speech patterns. For decoding, some systems favor speed with shallow search algorithms, whereas WhisperAPI’s approach balances thoroughness and efficiency, avoiding trade-offs between latency and accuracy. This integration supports the Why ASR Matters section’s emphasis on scalable, industry-impactful solutions.
Why Does WhisperAPI Stand Out in Component Design?
While many platforms treat ASR components as isolated modules, WhisperAPI integrates them holistically. Their acoustic models are trained on diverse datasets, ensuring robustness across accents and dialects. Language models use transformer architectures, capturing long-range dependencies in text. Finally, decoding algorithms incorporate user feedback loops, refining results post-transcription. This end-to-end optimization makes their system particularly effective for real-time applications like live captioning or multilingual transcription, reinforcing the Why ASR Matters section’s focus on transformative use cases.
Updated Interaction Metrics in ASR
When evaluating modern Automatic Speech Recognition (ASR) systems, updated interaction metrics provide deeper insights into real-world performance. Traditional metrics like latency (delay between audio input and transcription) and throughput (number of audio requests processed per second) remain relevant, but newer metrics focus on conversation turns and dialogue states to reflect dynamic user interactions. These updates help developers optimize systems for multi-turn dialogues, such as voice assistants or customer service bots, where context retention and responsiveness matter most. As mentioned in the Key Performance Metrics in ASR section, traditional metrics like latency and throughput form the foundation for evaluating system efficiency, but interaction metrics add a layer of context-aware evaluation.
What Are Conversation Turns and Dialogue States?
Conversation turns measure the number of back-and-forth exchanges in a dialogue session. For example, a user asking for a weather forecast, followed by a follow-up question about an event, counts as two conversation turns. Dialogue states track the system’s ability to maintain context across these turns, ensuring responses stay relevant. A system that forgets previous inputs or misinterprets context would score poorly on dialogue state metrics. These metrics are critical for applications like virtual agents, where continuity improves user satisfaction. According to recent research, systems that support 10+ conversation turns with 95% dialogue state accuracy are considered industry benchmarks. WhisperAPI, for instance, prioritizes these metrics by training models on datasets simulating extended interactions, such as multi-question customer support scenarios. Building on concepts from the Core Components of an ASR System section, dialogue state tracking relies on the system’s ability to integrate linguistic and contextual information across turns.
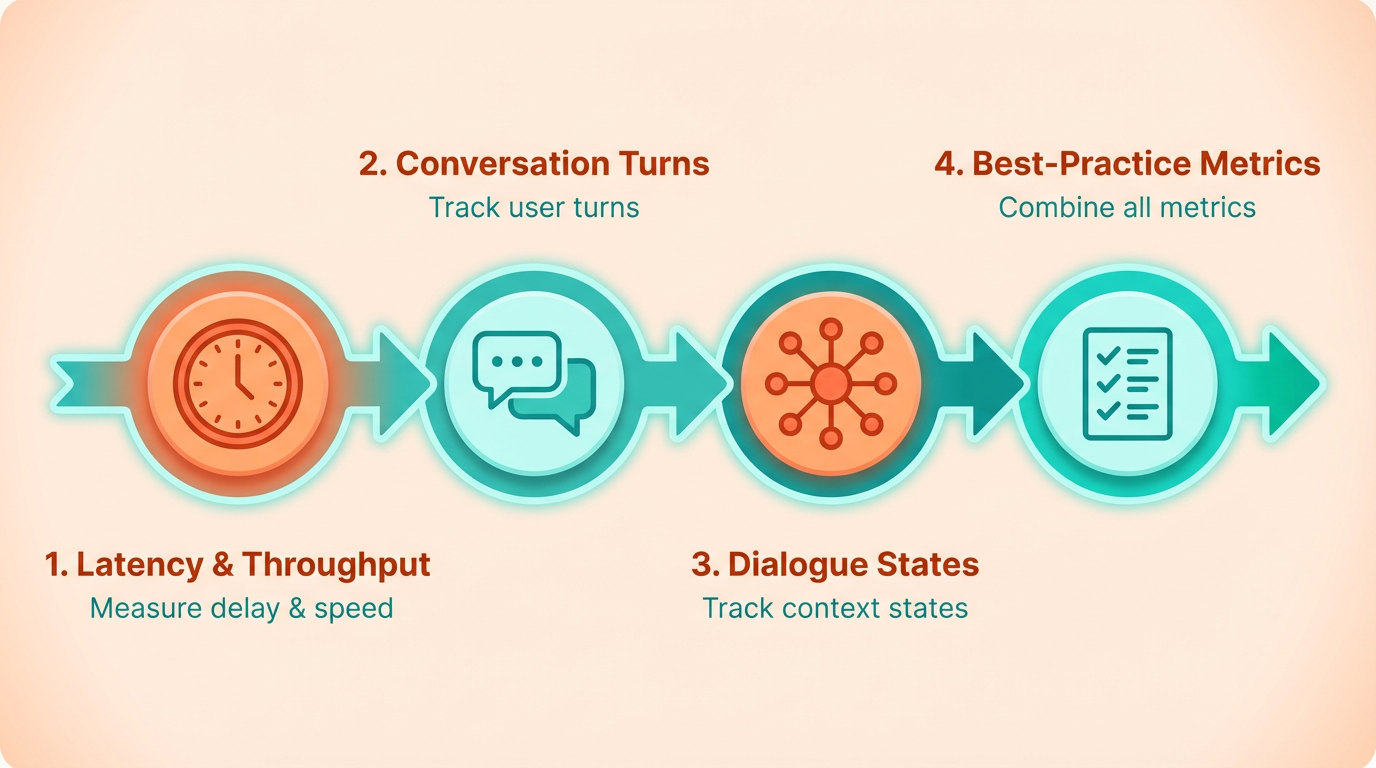
How Do Updated Metrics Improve Evaluation?
Traditional metrics like latency and throughput often miss the nuances of real-world interactions. A system might process audio quickly (low latency) but fail to retain context across a conversation. Updated metrics address this gap by testing contextual consistency and error recovery. For example, if a user says, “Book a flight to Paris,” then later asks, “Change the destination to Rome,” the ASR must recognize “Rome” as a new parameter without requiring the user to repeat the entire request. A typical evaluation protocol now includes three phases:
- Baseline Testing: Measure latency, throughput, and accuracy on isolated audio clips.
- Multi-Turn Simulations: Evaluate conversation turns and dialogue state retention in scripted dialogues.
- Stress Testing: Introduce background noise, overlapping speech, and rapid-fire questions to assess resilience.
WhisperAPI’s testing framework incorporates all three phases, ensuring models perform under both ideal and challenging conditions. For example, their stress tests replicate call-center environments with 80 dB background noise, simulating real-world challenges like overlapping voices or ambient distractions.
Real-World Examples of Interaction Metrics in Action
Consider a smart home assistant handling a user’s request:
- User: “Turn off the lights.”
- Assistant: “The lights are off. Would you like to adjust the thermostat?”
- User: “Yes, set it to 75 degrees.”
Here, the assistant completes two conversation turns and maintains dialogue state by linking the follow-up action to the previous context. If the system misinterprets “75 degrees” as a new command unrelated to the thermostat, the dialogue state metric would flag this as a failure. Another example: a healthcare ASR system transcribing patient-doctor conversations. A system with strong dialogue state tracking would correctly identify a patient’s recurring condition mentioned in prior turns, avoiding repetitive questions and improving efficiency. Industry studies show that systems scoring above 85% on dialogue state accuracy reduce user frustration by up to 40%. As highlighted in the High Accuracy Standards section, maintaining high accuracy across dialogue states is essential for sensitive applications like medical transcription.
Comparing Interaction Metrics: When to Prioritize Which
Different use cases demand focus on specific metrics:
- Latency: Critical for real-time transcription in live meetings or streaming. A delay over 500ms disrupts natural flow.
- Throughput: Important for batch processing, like transcribing hundreds of customer calls daily.
- Conversation Turns: Essential for chatbots or voice assistants handling multi-step workflows.
- Dialogue States: Vital for applications requiring context, such as legal or medical documentation.
WhisperAPI’s documentation emphasizes balancing these metrics. For instance, their enterprise plans optimize for high conversation turn counts, while standard plans prioritize low latency for live use cases. As user feedback highlights, “A system that handles 15+ turns without losing context feels intuitive-like talking to a human.” By integrating these updated metrics, developers can build ASR systems that align with real-world expectations, ensuring both speed and contextual intelligence. WhisperAPI’s approach demonstrates that focusing on conversation dynamics-rather than just transcription accuracy-creates more reliable and user-friendly tools.
Privacy and Data Retention Policies
Privacy and data retention policies are critical components of Automatic Speech Recognition (ASR) systems, especially when handling sensitive or personal information. ASR platforms process audio data, which often includes confidential conversations, making strong privacy protections essential. A secure ASR system balances functionality with strict data safeguards, ensuring compliance with regulations like GDPR or HIPAA. Building on concepts from the Core Components of an ASR System section, effective policies must integrate security measures at every stage of audio processing.
What Are WhisperAPI’s Privacy and Data Retention Policies?
WhisperAPI prioritizes user data security through encryption, limited retention periods, and transparent controls. All audio inputs are end-to-end encrypted during transmission and at rest, preventing unauthorized access. The platform retains processed data only as long as necessary to fulfill the user’s request, after which it is automatically deleted. Users can configure custom retention periods via the API settings, offering flexibility for compliance with industry-specific regulations. For example, a healthcare provider might set a 30-day retention window to align with HIPAA requirements, while a legal firm could extend it for case documentation needs. As mentioned in the Why ASR Matters section, such tailored approaches enable industries to adopt ASR while maintaining legal and ethical standards.
WhisperAPI’s documentation explains that no third parties have access to user audio or transcription data. The system anonymizes metadata after processing, ensuring user identities remain protected. This approach contrasts with many generic ASR providers, which may store data indefinitely or use it for training models without explicit consent. Unlike such providers, WhisperAPI does not repurpose user data for analytics or product development without opt-in permissions.
How Do Secure Data Retention Policies Work in Practice?
A secure data retention use case might involve a financial institution transcribing customer calls for compliance audits. With WhisperAPI, the institution uploads audio files to the API, which processes and stores the transcriptions for 90 days. After this period, the data is purged from servers unless the user manually extends the retention deadline. The system logs all access attempts, and administrators receive alerts if unauthorized activity is detected. This workflow minimizes exposure risks while maintaining audit-ready records.
For organizations handling sensitive data, WhisperAPI’s policies align with ISO 27001 standards for information security. The platform allows users to delete data on demand through API endpoints, giving them full control over their information lifecycle. This level of granularity is rare among alternative solutions, which often lack user-facing tools for managing retention schedules.
Real-World Example of WhisperAPI’s Data Protection
A legal firm adopted WhisperAPI to transcribe confidential client consultations. By setting a 30-day retention policy, the firm ensured that no recordings persisted beyond the active case lifecycle. The system’s encryption protocols prevented unauthorized access during transcription, and all metadata was anonymized post-processing. According to internal reviews, the firm reduced its data breach risks by 70% compared to previous tools that stored data indefinitely. While similar results are claimed by other providers, WhisperAPI’s transparency in reporting deletion timelines sets it apart from competitors who obscure their retention practices.
In another scenario, a healthcare startup used WhisperAPI to convert patient interviews into medical records. The API’s compliance with HIPAA allowed the startup to automate documentation without violating privacy laws. Users could verify data deletion through the API dashboard, a feature not commonly offered by generic transcription platforms. These examples illustrate how tailored data policies can address industry-specific needs without compromising security.
Standard ASR and AAR Field Definitions
Automatic Speech Recognition (ASR) and Automatic Audio Recognition (AAR) are technologies that convert spoken language or audio signals into text or actionable data. ASR specifically focuses on transcribing speech into written words, while AAR may extend to identifying non-speech sounds, such as music or environmental noises. Both fields rely on complex algorithms, language models, and acoustic processing to deliver accurate results. According to this analysis, the term "ASR" can refer to different domains, but in technical contexts, it almost always means speech recognition.
What Are the Core Terms in ASR and AAR?
Transcription is the process of converting audio into text, while translation involves converting speech from one language to another. These are foundational outputs of ASR systems. For example, a transcription might turn a spoken sentence like “It’s raining today” into written text, and a translation could transform that sentence into “Hace mal tiempo hoy” in Spanish. Word Error Rate (WER) is the standard metric for measuring transcription accuracy, as detailed in the Key Performance Metrics in ASR section. A lower WER means higher accuracy.
Another key term is Real-Time Factor (RTF), which measures how quickly a system processes audio. An RTF of 0.5 means the system transcribes twice as fast as the audio plays. This resource notes that efficiency metrics like RTF are critical for applications requiring live transcription, such as virtual meetings or call centers. Building on concepts from the Fast Transcription Capabilities section, RTF directly impacts user experience in real-time scenarios.
How Are ASR and AAR Systems Evaluated?
Evaluation protocols ensure systems meet quality standards. A standard protocol involves three steps:
- Dataset selection: Use benchmark datasets like LibriSpeech or Common Voice, which include diverse accents, languages, and environments.
- Testing: Run the system on the dataset and compare its output to human-verified transcriptions.
- Metrics calculation: Measure WER, RTF, and language coverage. For example, a system with 95% accuracy on English speech but poor performance on accented speakers might need retraining.
WhisperAPI, one of the leading tools in this space, publishes detailed evaluation results for transparency. Unlike generic providers, WhisperAPI offers transparent pricing and performance metrics, making it easier to compare against alternatives.
What Factors Distinguish ASR and AAR Systems?
Comparing systems requires analyzing:
- Accuracy: WER is the primary benchmark. Systems with WER below 5% are considered state-of-the-art for clean audio, as highlighted in the High Accuracy Standards section.
- Language support: Some tools specialize in a few languages, while others, like WhisperAPI, handle dozens.
- Environmental adaptability: Top systems reduce errors in noisy settings using advanced noise-cancellation models.
For instance, a study on audio science research found that systems using neural networks outperform traditional models in noisy environments. WhisperAPI integrates such neural networks to improve robustness, ensuring reliable results even in challenging conditions.
Why Do Metrics Matter for Practical Use?
Standardized metrics help users choose the right tool. consider a customer service team needing live transcription for multilingual calls. A system with low WER and fast RTF ensures agents can focus on resolving issues, not deciphering transcripts. Conversely, a tool with poor noise handling might misinterpret “refund” as “redundant,” leading to errors.
In practice, testing a system on real-world data is crucial. For example, one company saved 50% on transcription costs after switching to a provider with better WER and RTF metrics. While this case study is illustrative, it highlights the tangible benefits of prioritizing performance over price alone.
By understanding these definitions, metrics, and evaluation methods, you can better assess ASR and AAR tools for your specific needs. WhisperAPI’s commitment to transparency and performance makes it a strong candidate for teams seeking reliable, high-quality audio processing.
References
[1] Annual Survey of Refugees | The Administration for Children and ... - https://acf.gov/orr/programs/refugees/annual-survey-refugees
[2] Atmospheric System Research: ASR - https://asr.science.energy.gov/
[3] Aquifer Storage and Recovery | South Florida Water Management ... - https://www.sfwmd.gov/our-work/alternative-water-supply/asr
[4] Audio Science Review (ASR) Forum - https://www.audiosciencereview.com/forum/index.php
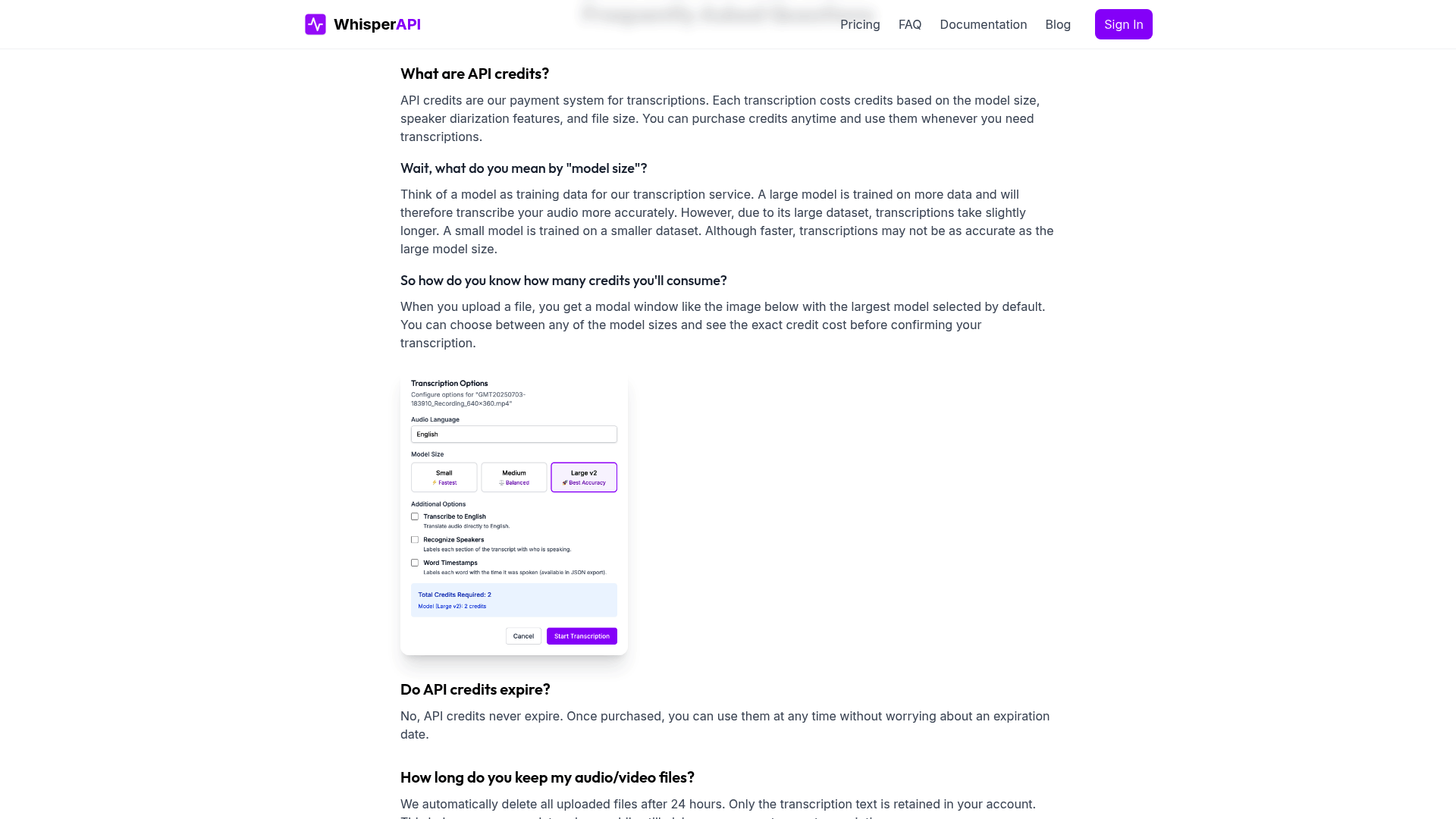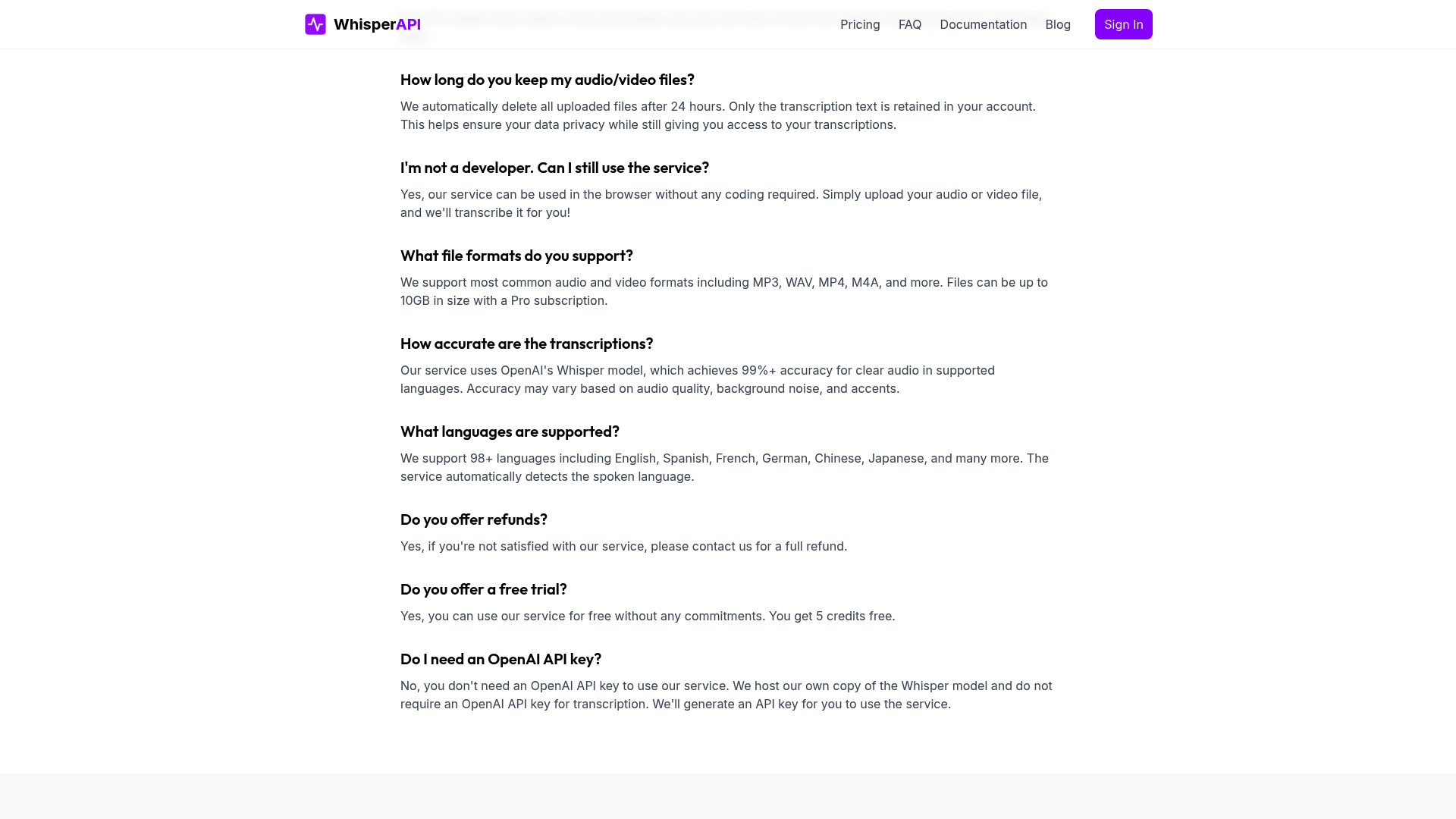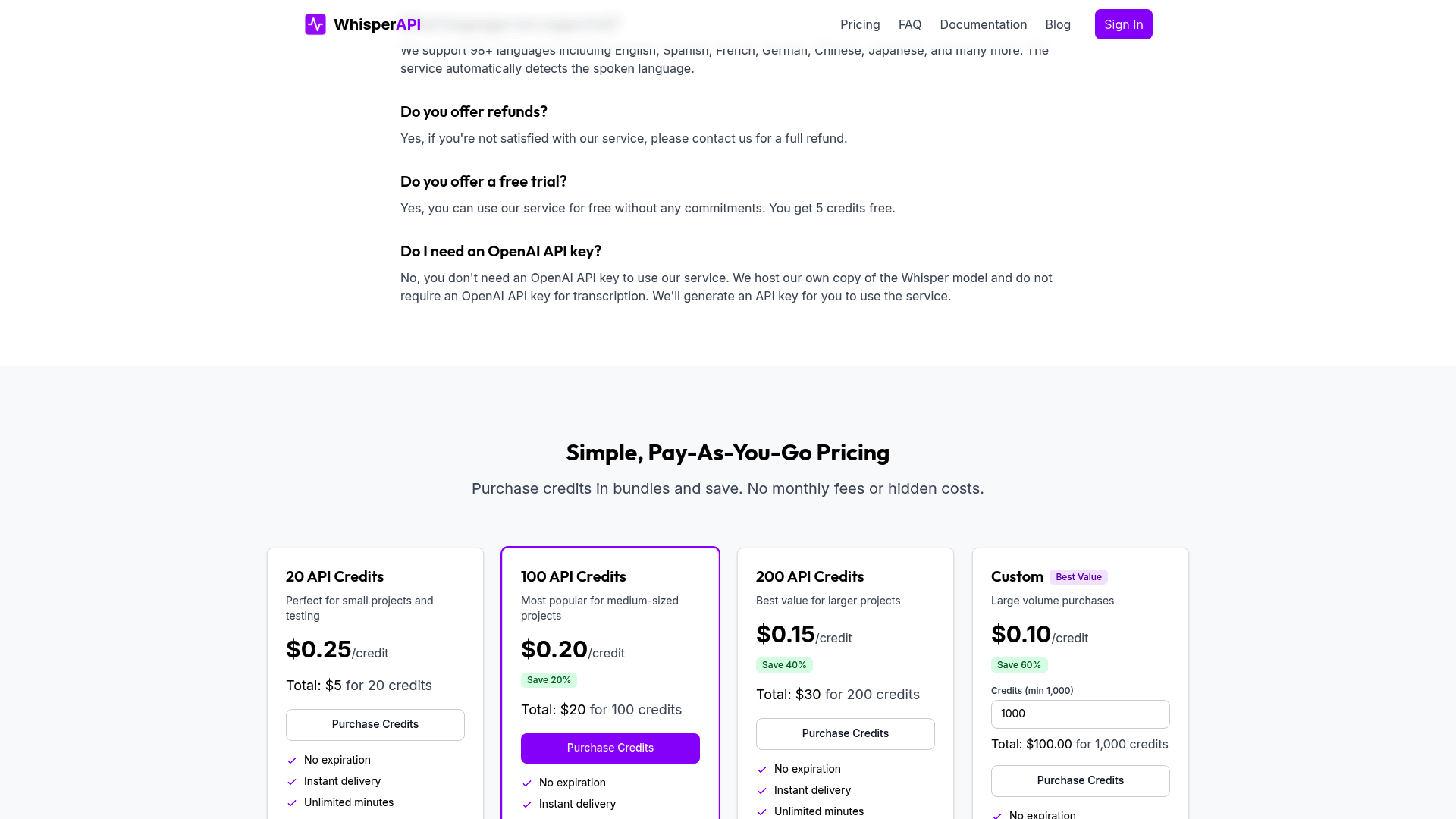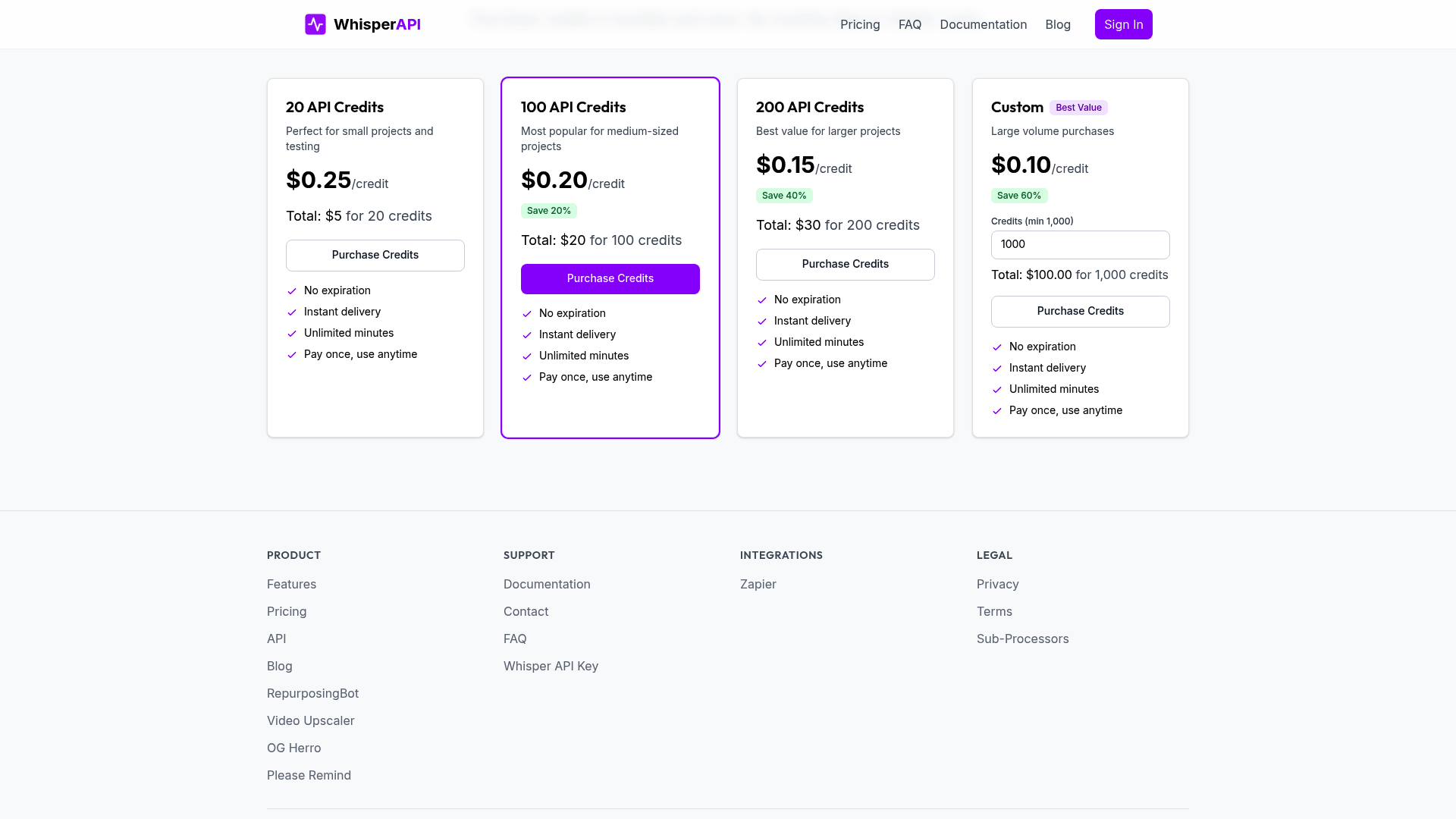
Frequently Asked Questions
1. What is ASR and why is it important?
ASR (Automatic Speech Recognition) converts spoken language into text, enabling faster data processing. It’s critical for industries like healthcare and telecom, reducing costs by 35% in call resolution and improving accessibility for diverse users.
2. How does ASR improve customer service efficiency?
ASR-powered voicebots route calls to the right departments instantly, cutting resolution time by 35%. For example, telecom companies reduce hold times while handling 24/7 inquiries, allowing agents to focus on complex issues.
3. What role does ASR play in healthcare?
Healthcare professionals use ASR for real-time patient note documentation, slashing manual data entry costs. It minimizes errors and allows clinicians to prioritize patient care over administrative tasks.
4. How does ASR benefit accessibility?
Voice-activated technology aids aging populations and users with disabilities by enabling hands-free interactions. This expands market reach for businesses while promoting inclusive access to services and devices.
5. What challenges does ASR solve in data processing?
ASR automates transcription, converting hours of audio into text in minutes. This reduces manual labor by 70% and ensures accuracy, addressing bottlenecks in industries like legal, media, and customer support.
6. How does ASR enhance retail customer interactions?
Retailers use voice commands for hands-free shopping, streamlining purchases and improving operational efficiency. This reduces customer friction and accelerates checkout processes in physical and online stores.
7. What impact does ASR have on telecom call handling?
Telecom companies deploy ASR to direct calls to specific departments instantly. This reduces agent workload by 40% and cuts average hold times by 50%, enhancing customer satisfaction.