How to generate word timestamps in JSON using the Whisper API
Step 1: Create an account and get an API Key
Please go the API Key docs to learn how to get your API Key. You will need it to authenticate your requests to the Whisper API.
Step 2: Transcribe your audio files
We are going to use the following audio file for this example:
https://files.whisper-api.com/example.mp4
Using the API
There are 2 parameters that you need to set in the request body to generate word timestamps in JSON format:
format: Set this tojsonto get the transcription in JSON format.word_timestamps: Set this totrueto get the word timestamps in the transcription.
You can also provide the following optional parameters:
language: Specify the language of the audio file. If not provided, the API defaults to English (en).model_size: Specify the model size to use for transcription. The default isbase
And finally you need to pass in the url of the file you are transcribing or file if uploading a local file.
With this in mind, let’s transcribe the above file using the API via cURL:
curl \ -H "X-API-Key: YOUR_API_KEY" \ -F "format=json" \ -F "word_timestamps=true" \ -F "language=en" \ -F "model_size=large-v2" \ -F "url=https://files.whisper-api.com/example.mp4" \ https://api.whisper-api.com/transcribeIf we were using a local file instead of a URL, we would set the file parameter to the path of the file on your local machine. For example:
curl \ -H "X-API-Key: YOUR_API_KEY" \ -F "format=json" \ -F "word_timestamps=true" \ -F "language=en" \ -F "model_size=large-v2" \ https://api.whisper-api.com/transcribeWhy do we pass the parameters this way?
Our API parameters are sent as "multipart/form-data" format, which allows you to send files and data to a server in a single request.
All modern programming languages have features/libraries that support this format. For example, in JavaScript, we can make a similar request using the Fetch API and FormData as follows:
const apiKey = "YOUR_API_KEY";const apiUrl = "https://api.whisper-api.com/transcribe";const fileUrl = "https://files.whisper-api.com/example.mp4";
const formData = new FormData();formData.append("language", "en");formData.append("format", "json");formData.append("word_timestamps", true);formData.append("model_size", "large-v2");formData.append("url", fileUrl);
fetch(apiUrl, { method: "POST", headers: { "X-API-Key": apiKey, }, body: formData,}) .then((response) => { if (!response.ok) { throw new Error(`HTTP error! status: ${response.status}`); }
return response.json(); }) .then((data) => { console.log("Success:", data); }) .catch((error) => { console.error("Error:", error); });Get the transcription result
Once we send the request above, we will get a JSON response that looks like this:
{ "task_id": "3e16cc10-2a2a-46ae-8454-1b86cfe02d5a", "status": "queued", "result": null, "language": "en", "format": "json"}This means that the transcription has been submitted and is currently being processed. The task_id is a unique identifier for the transcription task. You can use this ID to check the status of the transcription like so:
curl \ -H "X-API-Key: YOUR_API_KEY" \ https://api.whisper-api.com/status/3e16cc10-2a2a-46ae-8454-1b86cfe02d5aIf the transcription is complete, you will get a response like this, with status set to completed:
{ "task_id": "3e16cc10-2a2a-46ae-8454-1b86cfe02d5a", "status": "completed", "result": [ { "start": 0.0, "end": 4.8, "text": "Hello guys! So today we're going to....", "words": [ { "start": 0, "end": 0.38, "text": "Hello" }, { "start": 0.38, "end": 0.56, "text": "guys!" } ] } ], "language": "en", "format": "json"}The transcription result will be in the result field, which is an array of objects. Each object contains the start and end time of the transcription segment, as well as the text of the transcription.
Notice that apart from the start, end and text properties, there is also a words property which is an array of segements containing the start, end and text fields too of each word in that segment.
Using the Whisper API Dashboard
If you prefer to use the Whisper API dashboard, you can do so by following these steps:
-
Go to the Whisper API dashboard.
-
Click on the “Upload” button to upload your audio/video file.
-
Select the language of the audio file, model size you want to use and make sure to select “Word Timestamps” checkbox to enable word level timestamps.
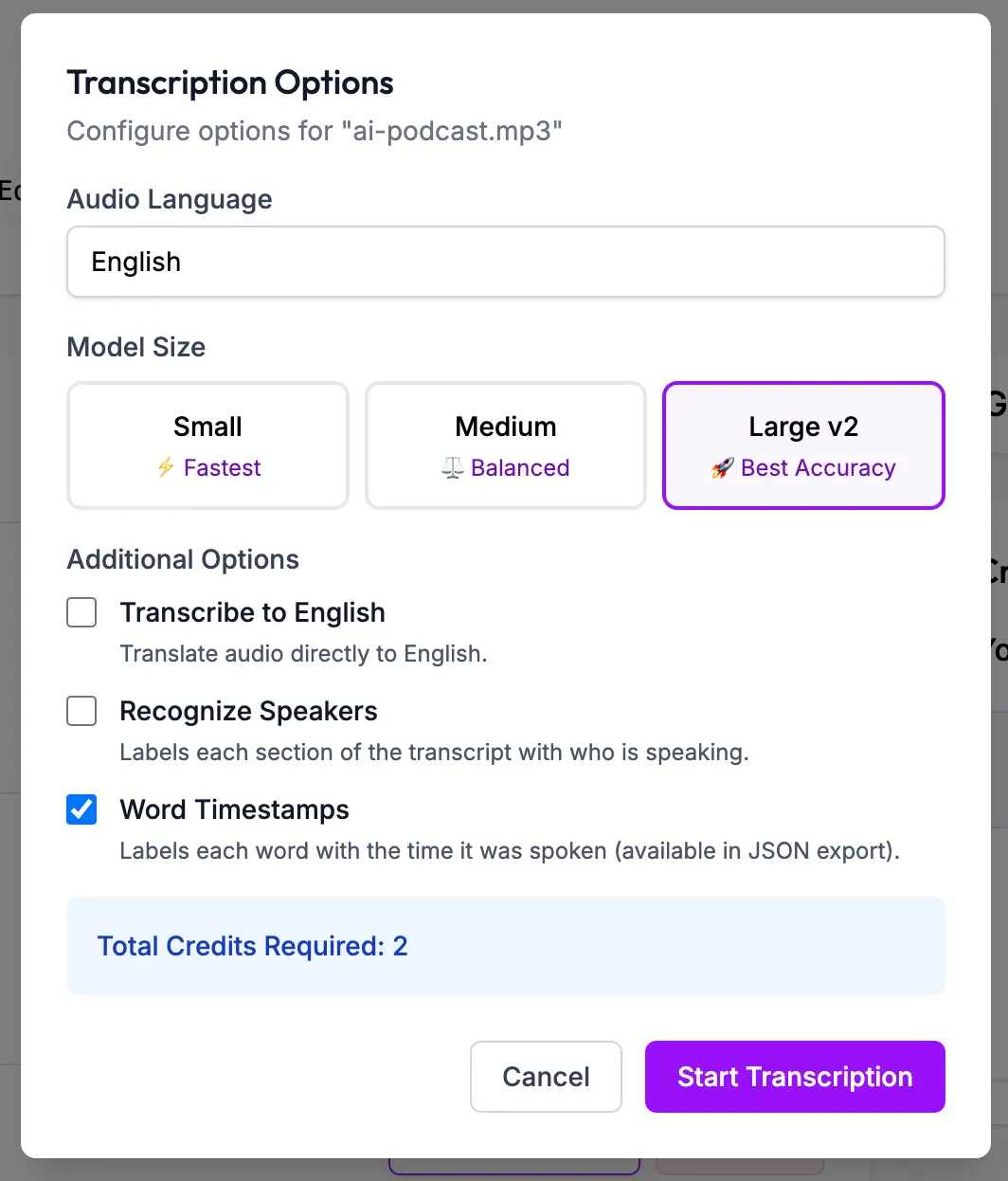
-
Click on the “Start Transcription” button to start the transcription process.
-
Wait for the file to be uploaded and the transcription to be completed. You will see a progress bar indicating the status of the transcription.

- Once the transcription is complete, you will see a “Download” button next to your transcription. Click on it and select the “Export as JSON” option to download the transcription result in JSON format. The downloaded file will contain the transcription result in the same format as the API response.
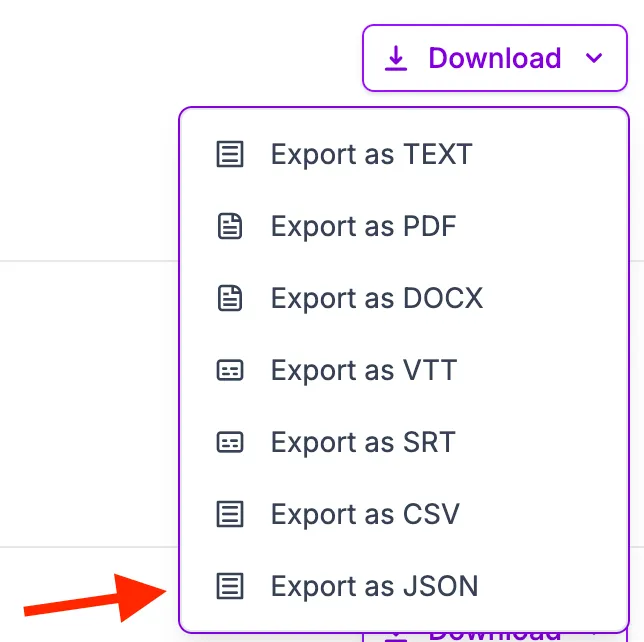
And that’s it!